Registration is closed.
CWI Lectures & Dijkstra Fellowship for Marcin Żukowski
Since 2019 and every five years, CWI celebrates the granting of the Dijkstra Fellowships to honour scientists who have accomplished groundbreaking research in mathematics and computer science. CWI has elected Marcin Żukowski for the 2024 Dijkstra Fellowship. With this honorary title, CWI recognizes his pioneering role in the development of database management systems that had great societal impact, and his successful entrepreneurial career. The Fellowship will be awarded on Thursday 21 November.
Share this page
When
21 nov 2024
from 10:15 a.m.
to
21 nov 2024
5:30 p.m.
CET (GMT+0100)
Where
CWI, Amsterdam Science Park Congress Centre, Science Park 125
Add

About the Dijkstra Fellowship
The Dijkstra Fellowship is named after former CWI researcher Edsger W. Dijkstra, who was one of the most influential scientists in the history of CWI. Dijkstra developed the shortest path algorithm, among other contributions. The first Dijkstra Fellowships were awarded to David Chaum and Guido van Rossum in 2019.
Dijkstra Fellowship 2024 for Marcin Żukowski
Marcin Żukowski started his career at CWI. He did his MSc and PhD research on database management system architectures in our Database Architectures (DA) group. As a PhD student under the supervision of Peter Boncz, he developed the innovative concept of vectorized execution to improve the performance of database queries. This research received the DaMoN 2007 Best Paper Award and also the CIDR 2024 Test of Time Award, established by the Conference on Innovative Data Systems Research (CIDR).
After his PhD, Żukowski co-founded CWI spin-off VectorWise (now Actian), turning his research into a high performance and highly scalable analytical database system. It became the blueprint for analytical databases, that is still widely used. After yielding a rapid technological and commercial growth, he left the company in 2012 to co-found Snowflake in Silicon Valley. Snowflake offered the first cloud-based data warehousing service that is truly designed for the cloud. Notable features are that it is an ‘elastically’ growing and shrinking system based on how busy it is, separating computation from storage, and automating many administration and configuration tasks. Snowflake uses vectorized query execution and lightweight compression methods in its columnar data storage, two techniques that were co-designed by Żukowski during his PhD years at CWI.
Role model
After leaving Snowflake earlier this year, Marcin Żukowski stays connected with academia by supervising students, publishing papers and taking part in computer science events. He is also an investor and advisor, supporting technology development and innovation in his home country Poland.
“Marcin is an excellent example of how to apply CWI's mission in practice. He used his PhD research at CWI to create versatile foundational software products that are now widely used, and shares his knowledge and experience with the public and in particular with young technology entrepreneurs”, CWI director Ton de Kok says.
CWI Lectures combined with Dijkstra Fellowship award
Topics of the CWI lectures are related to the architecture of data processing and analysis systems.
Speakers and topics:
Show
Title: Architecting the Snowflake Data Cloud

Abstract
In 2014, Snowflake emerged from stealth mode and announced a "data warehouse, built for the cloud". The system was built from the ground up, using a new architecture called the "multi-cluster shared data" architecture, which separates compute from storage, in order to allow users to take advantage of the elasticity of the cloud. In the decade since then, our system has evolved into a global, multi-cloud platform that supports data collaboration and many data processing workloads beyond data warehousing. In this talk, I will explain why the multi-cluster shared data architecture is well suited for the cloud, and how this architecture has enabled capabilities like massive scalability, automatic optimizations, and global secure data collaboration. Finally, I'll outline how the architecture has evolved over time as our capabilities have grown, and a few lessons learned along the way.
Biography
Allison Lee has spent the last two decades building commercial database systems. She currently leads the database engineering team at Snowflake, which owns the core query processing stack, Snowflake's internal key-value metadata store, and the data warehousing and hybrid transactional-analytic workloads. Allison joined Snowflake in 2013 as a founding engineer, and contributed to many of Snowflake's foundational components, including the query optimizer, metadata management, language extensibility, and data protection.
Prior to Snowflake, Allison worked on the Oracle database, with a focus on query optimizations for analytical workloads and bridging the gap between query optimization and execution with adaptive optimization techniques.
Allison holds dozens of patents in query optimization, data protection, and secure data collaboration.
Allison holds a Bachelor of Science and a Master of Engineering in electrical engineering and computer science from the Massachusetts Institute of Technology.
Title: What Goes Around Comes Around... And Around...

Abstract
Doesn't it feel like there is always a new crop of database management systems (DBMSs) pushing the idea that the relational model (RM) is outdated and SQL is dying? Proponents of vector databases have recently taken up this mantle fueled by interest in AI/ML technologies. Before that, NoSQL and MapReduce users claimed that RM/SQL was insufficient for "webscale" applications. And then, back in the 1990s, the object-oriented database vendors wanted every developer to switch to their non-RM, non-SQL systems. Database history does not repeat itself, but it indeed does rhyme.
In this talk, I will present the 60-year history of data modeling research and demonstrate why RM/SQL is the preferred default choice for database applications of any size. All efforts to completely replace the data model or query language have failed. Instead, SQL absorbed the best ideas from these alternative approaches and remains relevant for modern applications.
Biography
Andy Pavlo is an Associate Professor with Indefinite Tenure of Databaseology in the Computer Science Department at Carnegie Mellon University. He knows some pile about databases.
Title: Leaving The Two Tier Architecture Behind

Abstract
Analytical data management systems have long been monolithic monsters far removed from the action by ancient protocols. The common two- or three-tier architecture firmly placed data engines on dedicated, expensive hardware. Clients were reduced to politely asking for answers to their questions and then patiently waiting for an answer.
High-efficiency data processing methods like vectorized processing and morsel-driven parallelism greatly increase the capabilities of data engines. This coincides with both a staggering growth in hardware capabilities and a leveling-off of useful dataset growth. Together, those developments allow moving analytical engines everywhere, if properly designed.
The new class of in-process analytical engines allows them to move into any application process, which greatly streamlines data transfer, deployment, and management. This new class of systems also enables a whole new list of use cases, for example in-browser or edge OLAP, running SQL queries in lambdas and Big Data on laptops.
Biography
Prof. Dr. Hannes Mühleisen is a creator of the DuckDB database management system and Co-founder and CEO of DuckDB Labs, a consulting company providing services around DuckDB. Hannes is also Professor of Data Engineering at Radboud Universiteit Nijmegen and a senior researcher at the CWI Database Architectures Group. His main interest are - shockingly - analytical data management systems.
Title: What Table Representation Learning Brings to Data Systems

Abstract
We all observe the impressive capabilities of representation learning and generative models for text, videos, and images on a daily basis. Structured data such as tables in relational databases, however, have long been overlooked despite their prevalence in the organizational data landscape and critical use in high-value applications and decision-making processes. Learned representations, or embeddings, that capture the semantics of structured data can play a key role in making data systems more efficient, robust and accurate, at scale. Models that generalize to real-world databases are critical to make this work. In this context, I will discuss how rather compact and specialized column embeddings can be more effective than using GPT-something for table understanding, and reflect on the importance of capturing the core properties of relational databases in the embedding space. I will close by illustrating the value of embeddings for table retrieval to make LLM-powered query interfaces to structured data truly useful.
Biography
Dr. ir. Madelon Hulsebos is a tenure track researcher at CWI in Amsterdam. Prior to that, she was a postdoctoral fellow at UC Berkeley, and received her PhD from the University of Amsterdam for which she did research at MIT and Sigma Computing. Her general research interest is on the intersection of machine learning and data management, currently focusing on Table Representation Learning to democratize insights from structured data. Madelon founded the Table Representation Learning workshop at NeurIPS, and leads various other efforts in this space. She was awarded a BIDS-Accenture fellowship for her postdoctoral research on retrieval systems for structured data at UC Berkeley as well as a 5-year AiNed fellowship grant.
Title: The Future Of Cloud Database Systems

Abstract
Cloud computing is transforming the technology landscape, with database systems at the forefront of this change. A striking example is an online bookstore that has grown to dominate the database market. The appeal of cloud computing for IT users lies in several key factors: a reduced total cost of ownership through economies of scale and advanced services that minimize the burden of "undifferentiated heavy lifting". More broadly, cloud computing reflects a civilizational trend toward increased technological and economic specialization.
However, the current state of cloud computing often falls short of these promises. Hyperscalers are evolving into vertically integrated oligopolies, controlling everything from basic server rentals to high-level services. This trend is only accelerating, potentially leading to a future where hyperscalers establish software standards and design their own hardware, making it impossible to compete. Moreover, despite differences in branding, the major cloud providers are fundamentally similar, lacking interoperability and fostering vendor lock-in. As a result, we risk returning to the monopolistic conditions of the IBM and Wintel eras and ultimately technological stagnation due to limited competition.
Yet there is cause for optimism. Great technology can still succeed, as the multi-cloud data warehouse Snowflake has shown. The rise of data lakes and open standards, such as Parquet and Iceberg, further underscores the potential for interoperability and innovation. Additionally, there are orders-of-magnitude gaps between the price of existing cloud services and what is theoretically achievable, creating opportunities for disruption. These price gaps persist because cloud services are inherently complex to build, requiring redundant efforts and leading to high barriers to entry. For example, a DBMS might need a highly available control plane, a write-ahead log service, and distributed storage servers. None of these abstractions is available as a read-to-use service, which makes it difficult to enter the cloud database market. The current cloud landscape is more a result of historical circumstances than optimal design, leaving ample room for disruption.
In this talk, I will outline a blueprint for reinventing the cloud by focusing on three key areas: First, we need a unified multi-cloud abstraction over virtualized hardware. Second, we should establish new open standards for existing low-level cloud services. Third, we need abstractions that simplify the creation of new cloud services, such as reusable control planes and foundational components like log services and page servers. Together, this will make it significantly easier to build, deploy, and monetize new cloud services. Increased competition would commoditize foundational services and spur technological innovation.
Biography
Viktor Leis is a Professor in the Computer Science Department at the Technical University of Munich (TUM). His research focuses on designing cost-efficient data systems for the cloud, encompassing core database systems topics such as query processing, query optimization, transaction processing, index structures, and storage. He received his doctoral degree in 2016 from TUM and held professorships at the universities of Jena and Erlangen before returning to TUM in 2022.
Registration is closed. Please contact events@cwi.nl if you have any questions or if you can no longer attend.
Programme:
| Time | Subject |
|---|---|
|
09:30-10:15 |
Walk-in and registration |
|
10:15-10:30 |
Welcome |
|
10:30-11:15 |
Andy Pavlo: "What Goes Around Comes Around... And Around..." |
|
11:15-12:00 |
Hannes Mühleisen: "Leaving The Two Tier Architecture Behind" |
|
12:00-13:00 |
Lunch |
|
13:00-13:45 |
Allison Lee: "Architecting the Snowflake Data Cloud" |
|
13:45-14:30 |
Viktor Leis: "The Future Of Cloud Database Systems" |
|
14:30-15:00 |
Coffee break |
|
15:00-15:45 |
Madelon Hulsebos: "What Table Representation Learning Brings to Data Systems" |
|
15:45-16:30 |
Laudatio by Peter Boncz & Dijkstra fellow Marcin Żukowski: "The Importance of Product" |
|
16:30-17:30 |
Drinks |
Important information about the roadworks
Show
IMPORTANT NOTICE! If you come by car
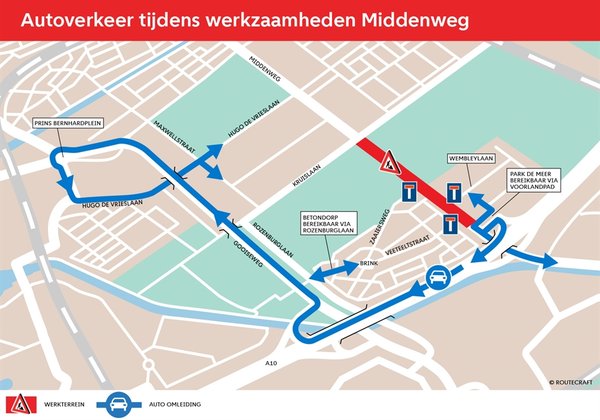
Maintenance work is being done on the Middenweg in Amsterdam. From 28 October 2024 until April 2025, the city will be working on the Middenweg between Kruislaan and the A10.
Traffic Impact
- From Monday, 28 October 2024 to April 2025, the Middenweg will be closed to cars between the A10 and Kruislaan. Signposted detours will be in place.
- Tram 19 will keep running. The Brinkstraat stop on line 19 will be moved during construction. R-Net buses will go via the A10/Gooiseweg to and from Amstel Station. Change to line 40 at Amstel Station if you're going to or from Science Park, sports fields or the Jaap Eden Ice Rink.
- Cyclists and pedestrians can still use the Middenweg, but the crossings at Wembleylaan and Zaaiersweg will be closed. The crossing at Veeteeltstraat stays open.
Impact on Science Park Access
Car traffic to and from Science Park will be redirected via the A10/Gooiseweg and Prins Bernhardplein, and then via Hugo de Vrieslaan to Middenweg and Kruislaan. R-Net buses to and from Amstel Station will no longer stop on Middenweg. Passengers going to Science Park should use GVB bus line 40 from Amstel Station. Science Park remains accessible as usual for cyclists and pedestrians.
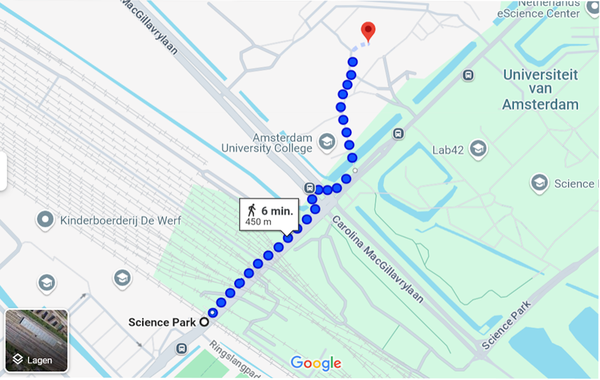
Directions from Amsterdam Science Park station (walking)
On foot from Science Park Station, pass under the railway tracks and continue straight ahead. Cross the road, keep left at the first turn, and pass through the open gate. From there, walk straight ahead and bear right; you will see the CWI building directly in front of you, with the Congress Center next door.
Marcin Żukowski:
